Over time, my Downloads folder accumulated thousands of PDFs, research papers, and invoices. Sorting them manually was a mammoth task I kept postponing. To solve this, I built a smart, local-first file organizer that understands document context and automates classification and placement. Below I’ll walk through a high-performance streaming architecture implemented in Go, and how I integrated Llama-3 (via MLX) to provide semantic understanding.
You can find the full source code on GitHub: jitendra-vadlamani/docs_organiser↗
How the System is Built
The system is built as a streaming pipeline using a classic producer-consumer pattern. This architecture allows it to remain scalable and memory-efficient as it traverses deep directory trees.
1. Streaming files instead of loading them
Instead of building a massive list of files in memory, the entry point is a recursive scanner that treats the filesystem as a stream. It pushes files into a processing queue as they are discovered, allowing the system to start working immediately rather than waiting for a full directory scan to complete.
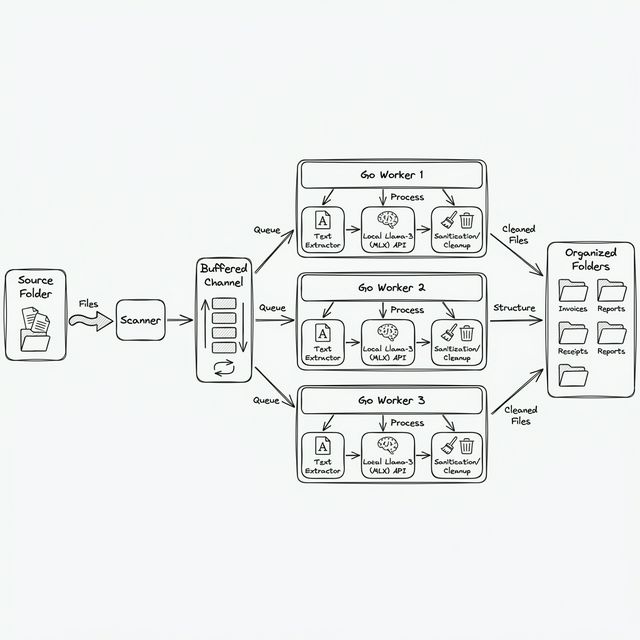
2. Extracting Content Snippets
Instead of processing every page, the system extracts a representative sample of text from the most relevant sections of each document. This ensures that the model stays focused on the key context needed for categorization while keeping the pipeline exceptionally fast. This approach allows the system to clean and sanitize data before it enters the model's attention context.
3. The Worker Pool
The heart of the pipeline is a worker pool that handles the heavy lifting. Each worker waits for tasks, extracts necessary text, coordinates with the AI engine, and manages the subsequent file movement.
for i := 0; i < p.Workers; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for job := range jobs {
p.processFile(ctx, job.Path)
}
}()
}While one worker is waiting ~500ms for an LLM response, the other four are busy extracting text or performing I/O operations. This masks the AI latency, keeping the pipeline flowing.
4. Late-Binding Classification
Categorization in this system is late-bound. The Go layer doesn't know the rules; it only provides the context. The System Prompt acts as the dynamic schema, allowing the AI to determine the category on the fly based on semantic understanding.
5. Structural Guardrails (Deterministic Correction)
One of the hardest parts of integrating AI into production systems is that LLMs are probabilistic. Sometimes they return perfect JSON. Sometimes they add conversational "fluff." Sometimes they hallucinate categories or directory structures. To bridge the gap, I implemented a Guardrail Layer:
- Strict Prompting: The system prompt demands a SINGLE JSON object with no markdown and no extra text.
- Output Parsing: A robust parser function strips away any conversational text by finding the first
{and last}. - Sanitization: The
SanitizeFilenamefunction ensures that category names are safe for the filesystem, replacing dangerous characters with underscores and collapsing redundant spaces. - Collision Hashing: If two files end up with the same AI-generated title, the
fileopslayer detects the collision and appends a short 8-character prefix of the file's SHA-256 hash to ensure uniqueness.
if _, err := os.Stat(dstPath); err == nil {
hash, _ := getFileHash(src)
dstPath = fmt.Sprintf("%s_%s%s", name, hash[:8], ext)
}Building the Local AI Engine
The system uses a local instance of Llama-3.2-1B-Instruct running on Apple’s MLX framework. By hosting a local server with an OpenAI-compatible API, I kept the AI logic decoupled from the core Go service.
On an M3 Pro, the 1B model categorizes a file in about 150-200ms. This local-first approach ensures that sensitive documents—bank statements, tax returns, and personal research—never leave my machine, keeping my data private on my NVMe drive while eliminating external API dependencies.
Engineering the Smart Layer
The real advantage isn't just "automatic sorting"—it's about turning static files into a dynamic, context-rich environment. When you can extract enough metadata programmatically, the traditional file hierarchy evolves from a static view into a flexible, dynamic one.
But building this requires more than just an LLM. It takes traditional backend rigor:
- Resilient Pipelines: Designing a streaming architecture that handles throughput without memory bloat.
- Concurrency & Control: Orchestrating worker pools to handle the latency of local inference.
- Reliability Shields: Building deterministic wrappers around probabilistic engines to ensure the filesystem remains a source of truth.
AI cannot solve "messy data" on its own; it requires a structured smart layer built with the same engineering discipline we've used for decades. By sitting this smart layer beside our existing rules and regex, we create systems that are finally as flexible as the data they manage.
What's Next?
This codebase is a playground for the future—integrating the observability and reliability required to make local AI a standard primitive in the backend stack.
References
- MLX Framework↗ - Apple's machine learning research framework for Apple Silicon.
- Go Concurrency Patterns: Pipelines and cancellation↗ - The foundational pattern used for the streaming architecture.
- Prompting Guide: Structured Outputs↗ - Techniques for ensuring models return reliable JSON.
- ledongthuc/pdf↗ - The library used for extracting text from PDF documents in Go.
- MLX Examples↗ - Real-world implementation details for running Llama-3 on Mac hardware.